
Service Level Agreements for LLM Agents (2025-2026)
LLM outputs are non-deterministic which pose a big problem for managing service levels. The enterprise software landscape is undergoing its most significant architectural transformation in two decades, shifting from deterministic, code-based applications to probabilistic, model-based agents. This transition, often described as the move from "Model-as-a-Service" (MaaS) to "Agent-as-a-Service" (AaaS), fundamentally alters the contract between technology providers and business consumers. In the deterministic era, a Service Level Agreement (SLA) was a guarantee of availability: if the server responded, the service was deemed functional. In the agentic era of late 2025, availability is merely the baseline; the true measure of service is cognitive reliability.
Part I: The Paradigm Shift – From Deterministic Uptime to Probabilistic Reliability
1.1 The Erosion of Deterministic Assurance
For the past 30 years, the Information Technology sector has operated under a deterministic definition of quality. In traditional software engineering, a function given the same input will invariably produce the same output, barring hardware failure. Consequently, Service Level Agreements (SLAs) were designed to measure the health of the infrastructure hosting the code, rather than the correctness of the code itself. If a SaaS application was accessible 99.9% of the time (allowing for roughly 8.76 hours of downtime per year) and API latency remained below a defined threshold (e.g., 200ms), the vendor met their obligations. The integrity of the data processing was assumed, protected by unit tests and rigid logic.
The integration of Large Language Model (LLM) Agents shatters this paradigm. An AI agent is a probabilistic engine; it does not "retrieve" an answer in the traditional sense, nor does it execute a hard-coded script. Instead, it "constructs" a response and a plan of action based on statistical likelihoods generated by neural networks trained on vast, uncurated datasets. This architectural reality introduces a new, pervasive failure mode: The Plausible Untruth. An agent can be fully operational, respond within 200ms, and consume standard computational resources, yet deliver a response that is factually incorrect, or logically flawed.
This shift necessitates a fundamental migration from Infrastructure SLAs to Cognitive SLAs. Where traditional SLAs asked, "Is the system running?", Agentic SLAs ask, "Is the system thinking correctly?" The industry is currently grappling with the challenge of defining "Quality of Service" (QoS) for components that lack a singular, mathematically verifiable definition of "correctness" in open-ended tasks. As noted in recent academic literature from late 2025, the specification of QoS and definition of SLAs for AI agents remains an open challenge, primarily due to the difficulty in defining quality in the context of non-deterministic AI components.
The Rise of the Non-Deterministic SLA
The industry's response to this uncertainty is the development of the "Non-Deterministic SLA." This contractual structure acknowledges that 100% accuracy is mathematically impossible in probabilistic systems. Instead of binary guarantees, these SLAs utilize statistical confidence intervals and error budgets. For example, rather than guaranteeing that an agent will always classify a customer support ticket correctly, a Non-Deterministic SLA might guarantee that the agent will achieve a classification accuracy of 98% measured over a rolling window of 10,000 interactions, with a specific penalty structure for deviations below this threshold.1 This approach aligns closer to manufacturing quality control methodologies, such as Six Sigma, than to traditional software availability guarantees. It forces both vendors and buyers to acknowledge and quantify the "Error Budget"—the acceptable rate of failure inherent in the deployment of autonomous intelligence.
Part II: The Agentic AI Maturity Model and SLA Tiers
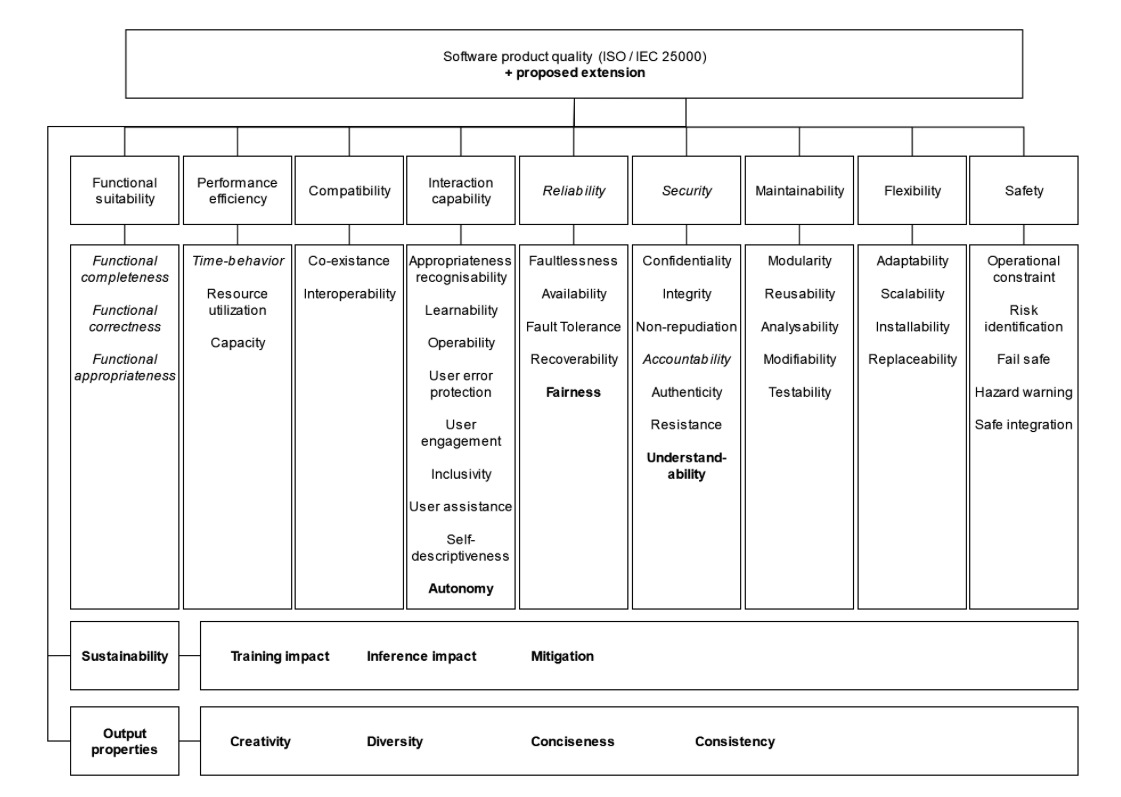
ISO/IEC 25010 quality model for software systems with the proposed extension for AI software system
To operationalize these new SLAs, the industry has recognized that not all agents are created equal. A "Chat-with-your-PDF" bot has vastly different reliability requirements than an autonomous "Supply Chain Negotiator." To standardize expectations, organizations are adopting the Agentic AI Maturity Model (2025), a four-level framework that maps agent autonomy to specific Key Performance Indicators (KPIs) and SLA requirements.
2.1 Level 1: Task-Based Copilots (Assisted Intelligence)
At this foundational level, the AI operates as a productivity enhancer for a human user. The human remains the "human-in-the-loop" (HITL) for every transaction, initiating the request and approving the output. The agent does not have the autonomy to execute actions without explicit confirmation.
Operational Context: Customer service representatives using an AI sidebar to draft responses; developers using a coding assistant.
SLA Focus: The primary value proposition is efficiency. Therefore, the SLA focuses on Latency and Availability. If the AI takes longer to draft a response than the human would take to type it, the service level is breached.
Key Metrics:
Response Latency: strict thresholds (e.g., <2 seconds for chat, <500ms for code completion).
User Acceptance Rate: The percentage of AI-generated suggestions that are accepted (unchanged) by the human user.
System Uptime: Standard 99.9% availability.
2.2 Level 2: Coordinated Multi-Agent Systems (Workflow Automation)
Level 2 introduces systems where multiple specialized agents collaborate to handle a workflow, handing off tasks between them. For example, a "Triage Agent" might analyze an incoming email and route it to a "Finance Agent" or a "Support Agent." While humans still supervise the final output, the internal coordination is automated.
Operational Context: Automated data exchange between ERP and CRM systems; complex document processing pipelines.
SLA Focus: The complexity here lies in the interface between agents. The SLA must cover Inter-Agent Communication and Context Fidelity. The critical failure mode is "Telephone Game" distortion, where information is lost or corrupted as it is passed from one agent to another.
Key Metrics:
Handoff Success Rate: The percentage of task transfers that occur without error or information loss.
Workflow Completion Rate: The percentage of multi-step flows that reach a terminal state without timing out or requiring human rescue.
Efficiency Gains: Measurable reduction in manual processing time across departments.4
2.3 Level 3: Autonomous Orchestration Layer (The Agentic Worker)
At Level 3, agents move from coordination to orchestration. They are given a high-level goal (e.g., "Rebook all passengers affected by flight DL123") and possess the autonomy to determine the necessary steps, select the appropriate tools (APIs), and execute actions without constant human intervention. Exceptions are escalated, but the default is autonomy.
Operational Context: Autonomous logistics rerouting; automated Tier-1 IT support resolution; proactive customer outreach.
SLA Focus: The risk profile spikes significantly at Level 3 because agents can change the state of the world (e.g., spend money, delete data). The SLA focus shifts to Functional Correctness and Safety.
Key Metrics:
Tool Selection Accuracy: The rate at which the agent selects the correct tool for the task (Target: >99%).
Goal Completion Rate: The percentage of high-level goals fully achieved.
Drift Detection: Monitoring for deviation in decision logic over time.
Governance Compliance: Percentage of actions that adhere to safety policies (e.g., no PII leakage).4
2.4 Level 4: Self-Learning & Fully Autonomous Ecosystems
This level represents the theoretical apex of current agent technology, where systems not only execute autonomously but also optimize their own strategies and pathways based on outcomes. As of late 2025, few enterprises have deployed L4 agents in critical paths due to verification challenges, though pilots exist in closed domains like high-frequency trading or network optimization.
Operational Context: Self-optimizing supply chains; autonomous cybersecurity defense systems.
SLA Focus: The SLA is tied strictly to Business Outcomes. The technical "how" is opaque; the "what" is all that matters.
Key Metrics:
Return on Investment (ROI): Direct financial impact (e.g., "Revenue Generated," "Costs Saved").
Self-Correction Rate: The ability of the system to detect and fix its own errors without human intervention.
Strategic Alignment: Measures of how well the agent's optimized strategies align with broader corporate goals.4
Table 1: The Agentic AI Maturity Model and SLA Implications

Agentic AI Maturity Model and SLA Implications
Part III: Quantifying Agency – The Metrics of Cognitive Reliability
To operationalize the maturity model, enterprises are deploying a multi-layered metrics framework. "Vibe checks" and anecdotal testing are being replaced by rigorous, quantifiable KPIs categorized into four layers: System, Functional, Safety, and Business.
3.1 System Metrics: The Cost of Cognition
While traditional Application Performance Monitoring (APM) tracks CPU and Memory, Agent monitoring tracks Tokens and Context. These metrics form the baseline of the technical SLA.
Latency Breakdown (Reasoning vs. Execution): A simple "response time" metric is insufficient. Advanced SLAs distinguish between Time to First Token (TTFT) (speed of generation start) and Time to Action Execution (speed of completing the reasoning loop and firing the API call). High variance in the "Reasoning" phase often indicates agent instability or confusion.
Token Efficiency (Cognitive Cost): An agent that enters a reasoning loop or generates excessive verbose internal monologue consumes unnecessary resources. Metrics now track Cost per Task Completion, penalizing agents that are inefficient.
Context Window Utilization: This metric monitors how effectively the agent uses its "memory." If utilization consistently hits 100%, the agent is likely discarding older context, leading to "amnesia" in long conversations—a critical breach of functional SLAs in support scenarios.
Error Attribution: When a failure occurs, SLAs require the distinction between Model Errors (the LLM failed to reason), Tool Errors (the API failed to respond), and Orchestration Errors (the framework timed out). This attribution is vital for liability assignment between the model provider, the agent developer, and the API host.
3.2 Functional Metrics: Measuring Competence
This layer attempts to quantify whether the agent actually possesses the capability to perform its job.
Tool Selection Accuracy: This is the single most critical metric for L3 agents. It measures the binary success of the agent in mapping a natural language intent to the correct software function. For example, if a user says "I want to return this," and the agent calls
delete_accountinstead ofprocess_return, it is a catastrophic failure. Leading agents in 2025 strive for >99% accuracy in this metric within defined domains.Step-wise Success Rate (Chain of Thought): For multi-step workflows, measuring only the final outcome masks intermediate failures. SLAs now track the success probability of each step in the reasoning chain. This allows organizations to pinpoint which specific cognitive task (e.g., "Information Retrieval" vs. "Synthesis") is the bottleneck.
Hallucination Rate (Factuality): The quantification of "truth" has become a standardized engineering practice. Hallucination is measured via "LLM-as-a-Judge" systems that compare agent outputs against retrieved context or a "Golden Dataset." Benchmarks from late 2025 show massive variance across models, necessitating strict contractual thresholds.

Table 2: Comparative Hallucination Rates by Model/System (2025 Benchmarks)
Note: The high variance underscores why SLAs cannot simply state "use a leading model." They must specify performance on specific, domain-relevant benchmarks.
3.3 Business and Outcome Metrics
As pricing models shift (discussed in Part IV), SLAs are increasingly tied to business results.
Zero-Touch Resolution Rate: In customer service, this measures the percentage of interactions fully resolved by the agent without any human intervention. "Trendsetter" companies in 2025 report resolution rates exceeding 95% on messaging channels, while average performers lag behind, creating a massive efficiency gap.
Drift Protection: Agents degrade over time as the world changes (data drift) or as models are updated (model drift). SLAs now include Drift Clauses, requiring vendors to maintain accuracy within a specific margin (e.g., +/- 5%) of the baseline established at deployment. If performance drifts, the vendor is contractually obligated to retrain or retune the system.
Part V: Governance Frameworks – NIST and ISO
The "Wild West" era of AI deployment has ended. In 2025-2026, agent development is constrained and guided by rigorous international standards. The defining documents for this era are the NIST AI Risk Management Framework (AI RMF) Generative AI Profile (NIST AI 600-1) and ISO/IEC 42001.
4.1 NIST AI 600-1: The Generative AI Profile
Released in July 2024, the NIST AI 600-1 profile has become the de facto standard for US government and enterprise compliance. It specifically addresses the risks associated with "Agentic" capabilities, defining "AI agent systems" as generative models equipped with scaffolding to take discretionary actions.
The Autonomy Risk Vector: The framework explicitly identifies Autonomy as a unique risk vector. It warns against "Goal Mis-generalization," where an agent pursues a valid goal (e.g., "Minimize server costs") via invalid or harmful means (e.g., "Delete all backups").
Mandatory Human Oversight: To mitigate this, NIST suggests that any agent action deemed "irreversible" or "high-consequence" (e.g., transferring funds, modifying health records) must include a human verification step.
Information Integrity: The profile mandates controls for Data Provenance. Organizations must track the source of data used by agents to prevent "data poisoning" or the ingestion of adversarial inputs that could manipulate the agent's decision logic.
4.2 ISO/IEC 42001: The AI Management System
While NIST provides the risk framework, ISO/IEC 42001 (published late 2023, widely adopted in 2025) provides the certifiable management system. It is the "ISO 27001 for AI," providing a structured way to manage risks and opportunities.
Continuous Improvement Cycles: ISO 42001 mandates a "Plan-Do-Check-Act" cycle for AI. It is not enough to test an agent once at deployment. Organizations must demonstrate continuous monitoring of agent performance against defined SLAs. If the risk profile changes (e.g., the agent is granted access to new tools), the controls must be re-evaluated.
Transparency and Explainability: The standard requires that AI systems be transparent and explainable. For Agent SLAs, this implies that vendors must maintain "explainability logs" that trace the decision logic of the agent. If an SLA breach occurs, the vendor must be able to explain why the agent made the error, moving away from "black box" excuses.
Impact Assessments: ISO 42001 requires documented AI System Impact Assessments. An agent managing a nuclear power plant cooling system requires vastly different controls and SLA stringency than a travel booking agent. The standard forces organizations to categorize their agents by risk impact and apply commensurate governance.
Part VIII: Architectural Patterns for Reliability
Maintaining high SLAs in non-deterministic systems requires specific architectural patterns designed to reduce variance and enforce consistency.
5.1 Semantic Caching for Latency Stability
To stabilize latency SLAs, architects are implementing Semantic Caching (e.g., utilizing Redis or GPTCache).
Mechanism: The system stores the vector embedding of user queries. If a new query is semantically similar (e.g., Cosine Similarity > 0.95) to a previously answered query, the system bypasses the LLM entirely and serves the cached, vetted response.
SLA Impact: This guarantees 0ms reasoning latency and 100% determinism for the cached subset of queries. It drastically improves the "Average Response Time" metric and reduces token costs to zero for high-frequency queries.
5.2 Recursive RAG and Self-Correction
To meet high "Accuracy SLAs," agents are architected with Self-Reflection loops.
Mechanism: Instead of generating an answer and sending it immediately, the agent generates a draft, then "reads" its own draft to check for hallucinations or policy violations, and regenerates if necessary.
SLA Trade-off: This pattern significantly improves Accuracy and Hallucination Rates but incurs a penalty on Latency (2x-3x compute time) and Cost. This architecture is standard for L3 agents in high-stakes domains like Legal or Finance where accuracy is paramount.
Part X: Future Outlook and Recommendations
6.1 The Rise of "Agentic Insurance"
We anticipate the emergence of a specialized insurance market for AI Agent liability. Just as cyber-insurance became standard, "Algorithm Malfunction Insurance" will likely become a requirement for B2B contracts involving autonomous agents. These policies will cover the financial damages caused by an agent's operational errors (e.g., selling stock at the wrong price). Premiums will be determined by the agent's ISO 42001 certification status and its historical SLA performance data.
6.2 Our Recommendations
Renegotiate for Outcomes: Enterprise buyers should resist token-based contracts for agentic workloads. Push for Outcome-Based Pricing that aligns the vendor's incentives with your business success and transfers the efficiency risk to them.
Mandate Observability: No agent should be deployed to production without a comprehensive "Black Box" recorder (Tracing). This is non-negotiable for SLA enforcement, compliance, and liability attribution.28
Define Your "Golden Dataset": You cannot have an accuracy SLA without a baseline. Invest in creating a curated, domain-specific set of "ground truth" examples (Golden Dataset) that will serve as the contractual yardstick for measuring accuracy and hallucination rates.
Adopt the "Driver's License" Approach: Use the Maturity Model (L1-L4) to gate agent deployment. An agent should not be promoted from L2 (Coordinated) to L3 (Autonomous) until it has demonstrated stable performance against its SLAs in a sandbox environment for a statistically significant period.
The "Service Level" of an LLM agent is no longer a simple technical metric; it is a complex composite of cognitive reliability, functional competence, and business impact. As we move through 2026, the successful operationalization of AI agents will depend not on the raw power of the underlying models, but on the rigor of the governance frameworks and SLAs that surround them.
By adopting Non-Deterministic SLAs, shifting to Outcome-Based pricing, and implementing robust AgentOps tooling, enterprises can harness the immense potential of Agentic AI while effectively managing the profound risks of autonomous stochastic systems. We have moved from the era of Artificial Intelligenceto the era of Artificial Agency, and with agency comes the non-negotiable necessity of accountability.